1. Introducción
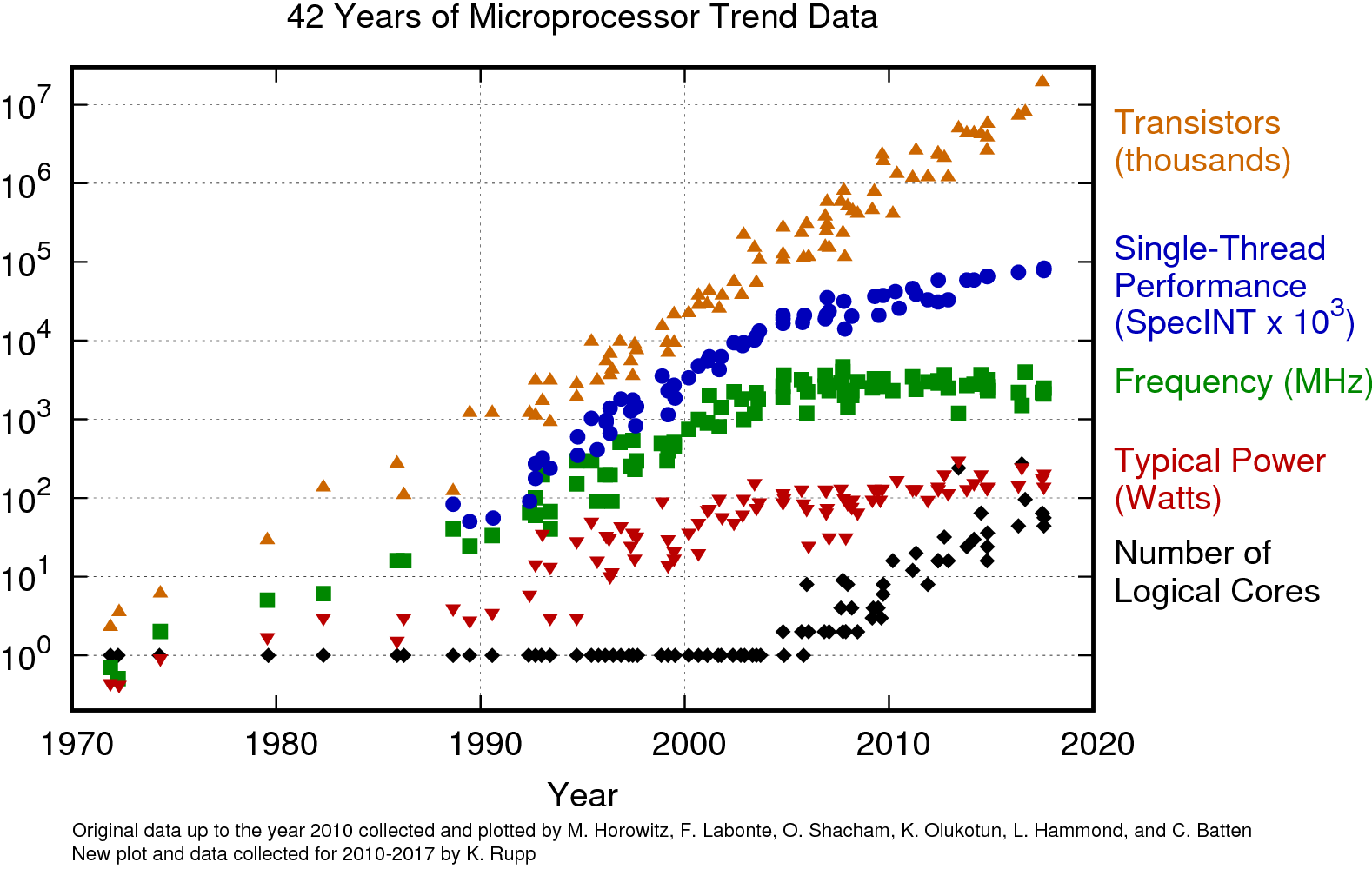
Desde los inicios de la computación, la velocidad de los procesadores ha incrementado exponencialmente. Los desarrolladores han visto cómo sus programas han aumentado de velocidad sin hacerles cambio alguno. Sin embargo, a partir del año 2005 aproximadamente, la velocidad de los procesadores se estancó, como se ve en la tendencia verde de frecuencia de la Figura 1. El estancamiento se debe a que no es factible incrementar la cantidad de transistores de una unidad central de procesamiento (CPU) porque produce un sobrecalentamiento que sobrepasa su capacidad de disipación de calor.
Para mantener el calor generado constante (tendencia roja de poder en Watts en la Figura 1), los fabricantes de procesadores encontraron que el camino para continuar incrementando el rendimiento sería cambiar de la fabricación de procesadores monolíticos (en inglés, single-core) a incluir más unidades de procesamiento (CPUs o núcleos) dentro del mismo procesador (en inglés multi-core). En la Figura 1 se ve cómo el número de núcleos (tendencia en negro) incrementa exponencialmente, mientras que la velocidad (tendencia en verde) se mantiene constante. Debe tomarse en cuenta que el eje-y en este gráfico no es lineal sino exponencial.
Los desarrolladores que quieran continuar aprovechando el incremento del rendimiento del hardware, deben modificar sus soluciones o diseñar nuevas en forma concurrente. Se ha intentado que la optimización de código existente se haga en forma automática por parte de software. Sin embargo, este ideal es actualmente un área de investigación con retos muy difíciles de superar, ya que el aprovechamiento del paralelismo usualmente exige encontrar un nuevo algoritmo, y por tanto, requiere re-diseñar las soluciones. Existen algunos conceptos relacionados a la concurrencia, como el paralelismo y la distribución. Conviene definir estos conceptos generales antes de continuar la discusión del hardware paralelo.
1.1. Conceptos generales
Concurrencia se va a definir en este documento como la habilidad de un sistema de realizar varias tareas a ciertas unidades de tiempo desde el punto de vista de un observador externo. Los seres humanos pueden realizar algunas tareas concurrentemente. Por ejemplo, una persona es capaz de conducir una bicicleta mientras silba una canción, y puede tertuliar con otras mientras cena. El antónimo de concurrencia es la serialización o secuencia, donde un sistema realiza una única tarea a la vez e inicia la siguiente sólo hasta que la anterior se haya completado. La diferencia entre estos dos conceptos se diagrama en la Figura 2.

Algunas tareas sólo pueden realizarse en forma serial por los seres humanos. Por ejemplo no se puede cursar la educación primaria y secundaria al mismo tiempo, sino que la educación secundaria se puede iniciar sólo hasta que la primaria se haya realizado por completo. La Figura 3 muestra un diagrama de tiempo, donde el eje-x indica los años en que una persona en promedio tarda en cursar varios niveles de educación en Costa Rica. El diagrama indica que una tarea inicia sólo hasta que la anterior haya concluido. Entre tareas hay tiempo que se dedica a cambiar de una tarea a la siguiente, lo que se indica con bordes punteados.

El concepto de concurrencia es flexible.
Cuando en lenguaje coloquial decimos que un estudiante está tomando cuatro cursos universitarios en un ciclo lectivo, sabemos que el estudiante no se divide para estar presente en aulas distintas donde se imparten cursos al mismo tiempo.
Sino que el estudiante alterna a la semana entre las lecciones y actividades de los cuatro cursos.
La Figura 4 muestra hipotéticamente cómo el estudiante alterna entre los cuatro cursos (rotulados c1 a c4) durante una semana.
Nótese por ejemplo que la primera tarea, el curso c1, es la primera a la que se le dedica tiempo, pero no concluye de inmediato, sino que el estudiante la continúa en el tiempo \$t_2\$.

Si una persona dice que está leyendo dos libros, sabemos que no los lee simultáneamente con cada ojo enfocando a un libro distinto, sino que la persona alterna entre las tareas leyendo trozos de un libro y luego trozos del otro. De acuerdo a nuestra nomenclatura, la persona no lee los libros en secuencia porque no inicia la lectura del segundo libro hasta que haya terminado de leer el primero por completo. De la misma forma, el estudiante tampoco toma los cursos serialmente porque no espera aprobar un curso para tomar el siguiente durante el mismo semestre. En ambos casos, las personas están haciendo cambio de contextos (en inglés, context switching). El cambio de contexto es una forma de concurrencia que alterna trozos de ejecución de distintas tareas.
Los sistemas operativos implementaron cambio de contexto antes de que aparecieran los procesadores multi-núcleo. Un usuario podía navegar por la web mientras reproducía música e imprimía un documento en una computadora con una única unidad de procesamiento (CPU). El sistema operativo dedicaba trozos de procesamiento de la única CPU disponible a estas tres tareas, junto con otras que se ejecutaban en primer y segundo plano. Dado que el procesador podía realizar operaciones a una velocidad muy rápida respecto a un humano, el usuario tenía la sensación de que ocurrían simultáneamente.
Cuando un sistema puede realizar dos o más tareas simultáneamente se dice que es paralelo.
Es decir, si se toma una instantánea infinitesimal del sistema, las dos o más tareas se están realizando efectivamente, sin alternar o serializar una o la otra.
Por ejemplo, un ciclista puede al mismo tiempo: pedalear, silbar, girar el manillar (manivela), y flexionar el cuerpo para distribuir el centro de gravedad, mientras ingresa en una curva, como ocurre entre los tiempos t2 y t3 en la Figura 5.
El ciclista no serializa estas actividades.
No tiene sentido que haga en el manillar todas las maniobras que ocupa en el recorrido mientras la bicicleta está estática, y una vez terminadas haga el trabajo en los pedales sin maniobrar más el manillar.

Dado que conducir una bicicleta no es una actividad serial, tiene que considerarse una actividad concurrente. Por tanto, el paralelismo es mayoritariamente una forma de concurrencia, como se aprecia en la Figura 2. De acuerdo a esta figura existen algunos casos sutiles donde una actividad puede ser paralela pero no concurrente, y se considerarán más adelante.
Tanto el paralelismo como los cambios de contextos son formas de concurrencia. Por tanto, si el ciclismo de montaña no es una actividad serial sino concurrente, el ciclista también podría conducir haciendo cambios de contexto. Por ejemplo, hace un giro en los pedales por un segundo, luego gira el manillar en el siguiente segundo sin pedalear, en el siguiente segundo flexiona el cuerpo sin pedalear ni girar el manillar, en el cuarto segundo sólo silba un trozo de su canción, en el quinto segundo únicamente pedalea, y así sucesivamente.
Conducir la bicicleta con cambios de contexto no es natural porque el ciclista puede realizar las tareas en paralelo. Cuando un sistema de cómputo puede ejecutar tareas simultáneamente, es porque el hardware tiene esta capacidad. Sin embargo, que el hardware sea paralelo no es una garantía de que las tareas se ejecuten paralelamente. Los sistemas operativos usualmente no corren sólo un programa a la vez, sino muchos en segundo plano. Dependiendo de la carga de trabajo que deba atender el sistema operativo, pueda que el hardware paralelo sea insuficiente y el sistema operativo tenga que recurrir a cambios de contexto.
Para ejemplificarlo en nuestra metáfora, el ciclista de montaña naturalmente haría las cuatro actividades en paralelo (pedalear, silbar, girar el manillar, flexionarse). Pero si en la curva se encuentra un riachuelo, el ciclista podría perder el equilibrio y tener que alternar entre pedalear y usar sus piernas para impulsarse con las rocas, prestar atención para no mojar los zapatos, girar el manillar sólo cuando la bicicleta avance y contorsionarse con más frecuencia. Es probable que interrumpa el silbido y reanude su canción hasta haber salido del riachuelo. Es decir, ante una situación de sobrecarga de trabajo, el ciclista saturó sus capacidades paralelas y tuvo que complementarlas con cambios de contexto.
Mientras que un ciclista puede realizar tareas en paralelo, otros ciclistas se pueden unir para realizar una tarea más compleja. Por ejemplo, una compañía local de ciclistas entregan comida a domicilio. Todos los ciclistas trabajan en paralelo para atender las órdenes de entrega. No es eficiente serializar las órdenes o hacer que los ciclistas cambien de contexto (órdenes). Los ciclistas deben tener un canal de comunicación (ejemplo, comunicación por radio) y usarlo para repartir las órdenes. Los ciclistas deben poder entenderse entre ellos, probablemente usando un mismo idioma.
Lo mismo ocurre en un sistema de cómputo. Varias computadoras conectadas por una red pueden usarse para resolver un problema. Estas computadoras deben ser uniformes, por ejemplo, tendrán el mismo modelo de procesador y el mismo sistema operativo. Se les suele llamar un clúster de computadoras, y por su uniformidad permitirán correr un mismo ejecutable entre ellas sin que el programador tenga que re-compilarlo.
Sin embargo, el mundo cada vez es más globalizado. La compañía de entrega de comida a domicilio por bicicleta podría internacionalizarse. Los ciclistas hablarían idiomas distintos, tendrían costumbres y leyes heterogéneas, usos horarios incompatibles, y hasta bicicletas con distintas características. La compañía deberá hacer ajustes en cada país para poder coordinar las entregas mundialmente.
De forma análoga, un sistema de cómputo podría consistir de computadoras heterogéneas, de distintos fabricantes, arquitecturas, sistemas operativos, y métodos de comunicación, a lo cual se le llama una malla de computadoras (en inglés, computer grid). Un ejecutable correrá sólo en un subconjunto de la malla. El programador no sólo tendrá que recompilar su código fuente a varias plataformas, sino que deberá diseñar e implementar protocolos de comunicación que permitan a los diversos programas distribuir la carga de trabajo. Este tipo de programación representa un paradigma llamado programación distribuida que usualmente es paralela pero no está limitada a ella, como se ilustra en la Figura 2. Por tanto, es la tercera forma de concurrencia.
Este curso trata sobre la programación concurrente, con un fuerte énfasis en la programación paralela, es decir, usando una máquina multi-núcleo, o varias de ellas con el mismo sistema operativo.
1.2. Hardware paralelo
La mayoría de computadoras modernas implementan de alguna forma la arquitectura de von Neumann. Esta arquitectura establece que las instrucciones y los datos se alojan en la memoria principal de la máquina. El procesador obtiene (fetch) instrucciones y datos de la memoria principal, realiza cálculos con ellos en la unidad aritmético-lógica (ALU), y típicamente almacena resultados de vuelta en la memoria principal. Industrialmente, la velocidad de los registros en las unidades de procesamiento es considerablemente mayor que la velocidad de la memoria principal (en el orden de una doscientas veces).

Una arquitectura paralela extiende la arquitectura de von Neumann al agregar varias unidades de procesamiento (CPU). Sin embargo, la memoria principal continúa siendo un único dispositivo y de menor velocidad. Por tanto, varias unidades de procesamiento compiten por la memoria, y esta crea una especie de serialización llamada cuello de botella de von Neumann que afecta negativamente el rendimiento. Se han implementado varias modificaciones a la arquitectura de von Neumann con el fin de incrementar el rendimiento paralelo. Algunas son:
-
Caché. A las unidades de procesamiento se les agregan memorias más pequeñas de diferentes velocidades, pero mayores que la velocidad de la memoria principal. A estas velocidades se les llaman niveles, tal que un caché de nivel 1 es más veloz que uno de nivel 2. El hardware automáticamente copia instrucciones y datos cercanos a la instrucción en ejecución en las memorias de caché, dado que es probable que la instrucción subsecuente se ejecute o que los datos cercanos sean usados. A este fenómeno se le llama principio de localidad (en inglés, principle of locality). Si un programa paralelo debe realizar muchas operaciones con pocos datos o pocas instrucciones que caben en las memorias caché, disminuirá los tiempos de espera por la memoria principal.
-
Paralelismo a nivel de instrucción (ILP, del inglés instruction-level parallelism). Ejecutar una instrucción requiere varios pasos, por ejemplo: traer la instrucción desde la memoria, decodificar la instrucción, ejecutar la operación en el ALU, escribir en la memoria, y guardar el resultado en un registro. En lugar de hacer estos pasos en secuencia, se pueden paralelizar uno tras otro como en una línea de producción, lo que se conoce como pipelining. Algunos procesadores pueden ejecutar dos o más instrucciones que son independientes al mismo tiempo, llamados procesadores superescalares.
Las dos formas de paralelismo anteriores son automáticamente realizadas por el hardware y el programador no tiene control sobre ellas (aunque sí puede estructurar sus programas para aprovecharlas). Por tanto, aunque sean arquitecturas paralelas, no es el tipo de interés en este curso. Hay varias arquitecturas paralelas que los programadores pueden controlar, y suelen clasificarse usando la taxonomía de Flynn.
1.2.1. Taxonomía de Flynn
La taxonomía de Flynn clasifica arquitecturas de computadoras de acuerdo a si permiten paralelismo de la tarea o paralelismo de los datos o ambos. Fue propuesta por el profesor Michael Flynn de la Universidad de Stanford en 1966. La Figura 7 ilustra las 4 categorías de la taxonomía de Flynn.

Un sistema de una instrucción y un dato (SISD, del inglés single instruction, single data) puede procesar sólo una instrucción en un dato a la vez. Corresponde al tipo de computadoras secuenciales, las más comunes antes de que la industria optara por las máquinas de varios núcleos (aproximadamente antes del 2005). Constan de una única memoria de control (CU, control unit) y una única unidad aritmético-lógica (ALU), por tanto, sólo ejecuta una única instrucción en un único dato por ciclo de reloj. Corresponde a la arquitectura de von Neumann original.
Un sistema de una instrucción y múltiples datos (SIMD, single instruction, multiple data) tiene una memoria de control (CU) y varios ALU, por tanto, puede ejecutar una única instrucción en cada ciclo de reloj, pero aplicarla a varios datos simultáneamente. Por tanto, es una arquitectura paralela que implementa paralelismo de datos, aunque las instrucciones sean ejecutadas secuencialmente. Dos tipos de arquitecturas SIMD son:
-
Procesadores vectoriales (vector processors). Son procesadores cuyas instrucciones trabajan no en un dato a la vez (escalar), sino en arreglos de datos (vectores). Por ejemplo, un procesador tradicional puede calcular la suma de dos registros y guardar el resultado en uno de ellos. Un procesador vectorial tiene varias ALU y puede calcular la suma (una instrucción) de un arreglo de números en un ciclo de reloj si el tamaño del arreglo es menor o igual que su cantidad de ALU.
-
Unidades de procesamiento gráfico (GPU, graphics processing units). Son similares a los procesadores tradicionales con algunas diferencias. Las instrucciones están orientadas al trabajo con gráficas, como suavizar una curva o aplicar efectos a píxeles, puntos, líneas o triángulos. Dado que estos elementos son usualmente independientes, las GPU son arquitecturas altamente paralelas, compuestas de múltiples shaders. Aunque las GPU se suelen clasificar como arquitecturas SIMD, pueden ejecutar instrucciones distintas en distintos datos.
Un sistema de múltiples instrucciones y un dato (MISD, multiple instruction, single data) ejecuta varias instrucciones en paralelo sobre el mismo dato. Son arquitecturas atípicas. Las pocas que existen generalmente se utilizan para tolerancia a fallos, donde varios chequeos se hacen en paralelo y un resultado general se guarda en una variable en memoria.
Un sistema de múltiples instrucciones y múltiples datos (MIMD, multiple instruction, multiple data) tiene varias unidades de control (CU) y varias unidades aritmético-lógicas (ALU), agrupadas en parejas. A cada pareja se le llama núcleo (en inglés, core) o unidad de procesamiento (CPU, del inglés central processing unit o simplemente processing unit). Dos o más núcleos pueden estar simultáneamente ejecutando instrucciones distintas y en datos distintos. Después del 2005 las arquitecturas SISD dejaron de ser las más comunes para dar paso a las arquitecturas MIMD. Las arquitecturas de múltiples instrucciones y múltiples datos se pueden clasificar en sistemas de memoria compartida y sistemas de memoria distribuida.
1.2.2. Sistemas de recursos compartidos
Un sistema de recursos compartidos (shared-resource system) consta de un conjunto de unidades de procesamiento autónomas conectadas a recursos que pueden acceder directamente, como el reloj del sistema y memoria principal. La comunicación entre las CPU y los recursos compartidos se hace a través de dispositivos de comunicación, como un buses (Figura 8) [Pach11]. De esta forma, todas las unidades de procesamiento comparten los mismos recursos, en especial, la misma memoria, y por tanto, pueden acceder a las mismas estructuras de datos en ella. El tipo de sistema de recursos compartidos más común son los procesadores multi-núcleo, que como se vio en la Figura 1 es la tendencia tomada por los fabricantes de hardware.

El dispositivo de comunicación de las unidades de procesamiento afecta significativamente su rendimiento. Los dos tipos de dispositivos de comunicación más comunes en los sistemas de recursos compartidos son los buses y los conmutadores de barras cruzadas.
Un bus consta de varios alambres paralelos que se conectan a todas las unidades de procesamiento, de tal forma que lo que una unidad escriba en el bus, todas las demás lo reciben casi simultáneamente. Los buses son baratos de implementar, pero tienen algunos inconvenientes. Si dos unidades escriben al mismo tiempo en el bus, la comunicación se estropeará, por lo que se se deben implementar mecanismos de control de comunicación.
Otro problema de los buses es que crea una serialización que afecta al paralelismo. Supóngase que se tienen dos unidades de procesamiento CPU1 y CPU2, y dos dispositivos de memoria M1, y M2. Si CPU1 necesita acceder intensivamente la memoria M1, y CPU2 ocupa acceder intensivamente la memoria M2, ambas comunicaciones se tendrán que alternar para usar el bus, lo que afecta el rendimiento. Un conmutador de barras cruzadas (crossbar switch) hace que las unidades de procesamiento se conecten a conmutadores (switches), los cuales detectan necesidades de comunicación y pueden aislar unas de otras de tal forma que puedan ocurrir en paralelo si son entre dispositivos independientes. Aunque los conmutadores de barras cruzadas tienen mayor rendimiento que los buses, su costo de fabricación es mayor.
1.2.3. Sistemas de recursos distribuidos
Un sistema de recursos distribuidos (distributed-resource system) consta de un conjunto de unidades de procesamiento autónomas, pero cada una tiene sus propios recursos privados, como su propio reloj del sistema y su propia memoria privada, por tanto no los comparte con otras unidades de procesamiento. Para poderse comunicar las unidades de procesamiento se envían mensajes explícitos a través de una red (Figura 9). Los sistemas de recursos distribuidos más comunes son los clusters que constan de un conjunto de computadoras homogéneas, llamadas nodos, conectadas por una red como Ethernet.

El medio de comunicación tanto en los sistemas de recursos compartidos como distribuidos afecta en el rendimiento de las aplicaciones, pero es especialmente crítico para los sistemas de recursos distribuidos. Típicamente se usan redes de computadoras, conectadas a través de topologías con redundancia de conexiones para permitir comunicaciones simultáneas entre nodos. El rendimiento de las comunicaciones es muy crítico y se mide con dos indicadores, cuya definición puede variar de acuerdo a los autores:
-
Latencia (latency). Es el tiempo transcurrido desde que el emisor inicia a transmitir datos y el momento en el que el receptor recibe el primer byte. Se mide en alguna unidad de tiempo, como segundos, horas, o mili-segundos.
-
Ancho de banda (bandwith). Es la tasa a la que el receptor recibe los datos a partir del momento en que llega el primer byte. Se mide en unidades de datos por unidades de tiempo, por ejemplo, bytes por segundo, o gigabits por minuto.
Si se transmiten \$s\$ bytes a través de una red con una latencia de \$L\$ segundos y un ancho de banda de \$b\$ bytes por segundo, el tiempo total en segundos que transcurre entre el momento en que el emisor transmite el primer byte hasta que el receptor recibe el último byte se llama tiempo de transmisión de mensaje \$T\$ y se calcula como:
\$T = L + \frac{s}{b}\$
1.3. Software paralelo
El hardware paralelo está por doquier, desde las nubes de computadoras hasta los dispositivos móviles. Lo mismo no se puede decir del software. Los desarrolladores deben conocer cómo escribir software que aproveche las capacidades del hardware paralelo para resolver problemas.
El objetivo principal de la computación como disciplina es la resolución de problemas con computadoras. Una computadora es una máquina electromecánica capaz de ser programada, y por tanto, de ser instruida para realizar tareas no preestablecidas desde su fabricación. Las computadoras ofrecen tres recursos que complementan las habilidades de los seres humanos: procesamiento, almacenamiento, y comunicación. El ideal de los profesionales en informática es aprovechar estos tres recursos para ayudar a las personas a tener una mejor calidad de vida. Existen prácticas socialmente aceptadas de cómo orquestar estos recursos para resolver problemas, a las cuales se les llaman paradigmas de programación. Es el tema de este curso el paradigma de programación concurrente.
1.3.1. Paradigma de programación concurrente
El paradigma de programación concurrente extiende a otros paradigmas, como el funcional o el imperativo, con dos conceptos principales, proceso e hilo de ejecución, con el fin de resolver problemas que requieren separación de asuntos e incrementar el rendimiento. Los conceptos de procesos e hilos son construcciones de los sistemas operativos, por tanto, se debe recurrir a teoría de este campo para definirlos.
Un proceso es una instancia de un programa en ejecución [Silb12]. Un programa es una entidad pasiva, normalmente un archivo en memoria secundaria (ej.: en disco o SSD). Cada vez que el usuario inicia un programa, por ejemplo haciendo doble clic sobre él en un explorador de archivos o escribiendo su nombre en la línea de comandos, el sistema operativo crea un proceso del programa. El proceso es una entidad activa, que ocupa memoria principal, procesamiento y puede comunicarse, en contraste al programa estático en disco. Un proceso puede comunicarse con el usuario a través de interfaz de comandos o de interfaz gráfica, como ocurre con una hoja de cálculo y con un navegador web, o puede correr en segundo plano.
Cada proceso es independiente de otro, y el sistema operativo debe asegurar esta protección. En condiciones normales un proceso no puede acceder a los recursos de otro, como la memoria, procesamiento, o comunicación. Si un proceso quiere comunicarse con otro, debe recurrir al sistema operativo como mediador. Un usuario puede iniciar varias instancias de un mismo programa. Por ejemplo, podría abrir dos instancias (procesos) del programa en disco de la hoja de cálculo. Si uno de los procesos se "cae", el otro proceso de la hoja de cálculo continuará ejecutándose sin ninguna afectación.
Cuando un programa corre, el sistema operativo crea un proceso y carga el ejecutable desde la memoria secundaria y distribuye su memoria principal en secciones, también llamados segmentos por razones históricas. Por tanto, la memoria de un proceso se divide en al menos cuatro segmentos, como se ilustran en la Figura 10 y se resumen a continuación.
-
Segmento de código (en inglés, code segment). Almacena las instrucciones del programa que serán ejecutadas por el procesador. También se le llama segmento de texto (en inglés, text segment).
-
Segmento de datos (en inglés, data segment). Almacena las variables estáticas o globales del programa, las cuales existen desde antes que la primera función del programa se ejecute y hasta que el programa termine su ejecución.
-
Segmento de memoria dinámica (en inglés, heap segment). Almacena los datos solicitados por el programador en la memoria dinámica. Alojar o remover datos en este segmento requiere intervención del sistema operativo.
-
Segmento de pila (en inglés, stack segment). Almacena las invocaciones de funciones y sus variables locales. Existe uno por cada hilo de ejecución del proceso, como se explica adelante.

Dentro de un proceso, la verdadera ejecución ocurre en al menos un hilo de ejecución. Un hilo de ejecución (en inglés, execution thread o simplemente thread) es un conjunto de valores (registros del procesador) que una CPU requiere como contexto para ejecutar una serie de instrucciones. El conjunto de valores incluye al menos, un identificador del hilo de ejecución dentro del proceso, un contador de programa (en inglés, program counter, también llamado instruction pointer) que indica la instrucción de código siendo ejecutada, y un puntero a su pila exclusiva para invocar funciones.
Un hilo de ejecución requiere un núcleo de CPU disponible para correr. Si no hay núcleos de CPU disponibles en un determinado momento, el hilo de ejecución tendrá que esperar hasta que alguno se libere (cambio de contexto). Cuando un programa es ejecutado (proceso), siempre inicia un hilo de ejecución principal, y finaliza cuando este hilo termina su ejecución. Los hilos de ejecución pueden crear más hilos, y hasta cierto punto, controlarlos.
Cada hilo de ejecución dispone de un segmento de pila exclusivo, en el cual se apilarán las invocaciones de funciones con sus variables locales. Las pilas permiten a los hilos ejecutar porciones de instrucciones del segmento de código en forma separada y concurrente. Los hilos no comparten sus pilas, es decir, un hilo de ejecución no puede acceder a la pila de otro, a menos que el programador utilice mecanismos de indirección explícitos como punteros en C o referencias en C++.
Todos los hilos de ejecución dentro de un mismo proceso corren código cargado en el segmento de código del proceso. Este código puede acceder a las variables alojadas en el segmento de datos y la memoria dinámica (heap). Por tanto, se dice que todos los hilos de ejecución dentro de un mismo proceso comparten el código, las variables globales, y datos en en memoria dinámica. Si un hilo modifica un dato en estos dos segmentos, los demás hilos del mismo proceso tendrán acceso a la modificación. Este esquema se llama concurrencia compartida, pues los hilos comparten los segmentos mencionados de su proceso. Dado que los procesos también permiten implementar concurrencia, pero no comparten sus recursos por protección del sistema operativo, ofrecen por tanto un esquema distinto, llamado concurrencia distribuida.
El paradigma de programación concurrente consiste en un conjunto de prácticas recomendadas sobre cómo utilizar los hilos de ejecución y los procesos para resolver problemas. A estos dos constructos se les llamará en este documento como trabajadores (workers), ya que metafóricamente actúan como los trabajadores que realizan las tareas de una organización. Los problemas donde estos constructos tienen utilidad son los que requieren separación de asuntos y rendimiento.
La separación de asuntos (separation of concerns) pretende mantener el código de diferentes responsabilidades separado, lo cual facilita la comprensión y el mantenimiento. Por ejemplo, un reproductor de DVD tiene el motor de rendering que envía audio y vídeo a los dispositivos de salida y la interfaz del usuario. La primera es intensiva en uso del procesador. Si se implementa en un único hilo de ejecución, la lógica estará mezclada y el programador deberá implementar código para vigilar en espacios regulares que el usuario no haya hecho algo en la interfaz, como presionar el botón de pausa para detener el motor de rendering. Si se implementan como dos hilos separados, uno se ocuparía del rendering y otro de la interfaz. El código es más fácil de leer y mantener [Will12].
El segundo fin de la concurrencia es incrementar el rendimiento de una solución, y por tanto, la cantidad de trabajo realizada por unidad de tiempo, lo que mejora la velocidad de respuesta al usuario (responsiveness).
Cuando un problema requiere separación de asuntos o tiene restricciones de rendimiento, el paradigma de programación concurrente ofrece los conceptos de proceso e hilo de ejecución (trabajadores). Para poderlos aplicar adecuadamente, el programador debe diseñar una solución siguiendo la estrategia de resolución de problemas llamada divide y vencerás. En general, el programador debe particionar el trabajo entre trabajadores. Existe dos formas de hacer esta división:
-
Paralelización de la tarea (task parallelism). Se divide la tarea en subtareas que pueden realizarse en paralelo. Por ejemplo, si 5 profesores deben revisar 100 exámenes todos con 10 preguntas, el profesor 1 podría revisar las preguntas 1 y 2 en todos los 100 exámenes, el profesor 2 revisaría las preguntas 3 y 4 en todos los 100 exámenes, y así sucesivamente. Cada profesor estaría concurrentemente haciendo una tarea distinta ("ejecutando diferentes instrucciones") en los mismos datos (los 100 exámenes). [Pach11]
-
Paralización de datos (data parallelism). Se dividen los datos en subconjuntos que pueden procesarse en paralelo. Por ejemplo, los 100 exámenes pueden dividirse en 5 grupos de 20 exámenes. Cada uno de los 5 profesores revisaría un grupo de 20 exámenes. Cada profesor estaría concurrentemente haciendo la misma tarea ("ejecutando las mismas instrucciones") en datos distintos (20 exámenes). [Pach11]
1.3.2. Cuándo es inapropiado
Al igual que los demás paradigmas, el paradigma de programación concurrente no es apto para todos los problemas. No se debe utilizar concurrencia cuando el beneficio no justifica el costo. Estos son algunos contextos donde no se debe implementar concurrencia [Will12]:
-
Cuando el código se torna difícil de entender, y por tanto, de mantener.
-
Cuando un hilo o proceso realiza una tarea muy corta, ya que no justifica el sobrecosto (overhead) que debe incurrirse en crearlo, lanzarlo o administrarlo.
-
Cuando se requiere lanzar una enorme cantidad de hilos o procesos, ya que saturarán la capacidad de paralelismo y el sistema operativo tendrá que recurrir a cambio de contextos, cuyo rendimiento puede resultar peor que el de un solo hilo. Un stack segment típico consume 1MB. Una máquina con 4GB de RAM no podría alojar más de 4096 hilos en memoria principal. Esta es una limitación importante en un servidor (web, o de bases de datos) que dispara un thread por cada conexión cliente.
Es normal que la aplicación termine implementando concurrencia sólo en ciertas partes del código, críticas de rendimiento. Por tanto, lanzar un hilo más no necesariamente incrementa el rendimiento, si no que dependiendo de las circunstancias, puede empeorarlo [Will12].
1.4. Diseño concurrente
Dado que los procesadores multi-núcleo son relativamente recientes, los lenguajes de programación ofrecen desde sus inicios soporte nativo para la programación serial. Por ejemplo, si en C/C++ se quiere que dos instrucciones o dos tareas se ejecuten una tras la otra, basta indicar su orden una línea tras la siguiente, como se ve en el Listado 1
task1();
task2();Si sabemos que si task1 y task2 son dos subrutinas habituales, la tarea task2 se ejecutará sólo hasta que la tarea task1 haya terminado su ejecución.
En caso extremo, si la invocación a task1() no llegara a terminar, task2 nunca se ejecutaría.
El cambio de contexto es una funcionalidad que implementan los sistemas operativos y los programadores de aplicaciones de usuario no pueden alterarlo, a menos que sean programadores del núcleo del sistema operativo. Por tanto, los lenguajes de programación no ofrecen funcionalidad de cambio de contexto a los desarrolladores.
(…)
El paradigma de programación concurrente no reemplaza otros paradigmas, sino que los extiende al agregar los conceptos de hilo de ejecución y proceso. De forma análoga, el diseño concurrente no reemplaza las formas de diseño de otros paradigmas, sino que los extiende. Por ejemplo, el cálculo lambda del diseño funcional se extiende con el símbolo de barra (|) en el cálculo π, los algoritmos del diseño procedimental marcan o agrupan instrucciones que pueden ejecutarse en paralelo, y el diseño orientado a objetos agregan las barras en UML. En la siguiente sección se discutirán dos actividades típicas del diseño concurrente y se ejemplificarán con algoritmos.
1.5. Descomposición y mapeo
Lo mínimo que diseñador debe indicar en un algoritmo para que aproveche las ventajas de la concurrencia, son los conjuntos de instrucciones que pueden ser ejecutadas simultáneamente [Gram03], o los conjuntos de datos que pueden ser procesados simultáneamente. En cualquier caso, el diseño concurrente consiste en dividir una computación en trozos y asignarlas a diferentes ejecutantes (trabajadores).
La descomposición es el proceso de dividir una computación en partes más pequeñas, de tal forma que estas partes puedan ser ejecutadas concurrentemente. Los tamaños de las partes pueden ser arbitrarios, pero una vez definidos, se considerán unidades indivisibles de computación. == Concurrencia compartida
1.6. Concurrencia imperativa (Pthreads)
Recuerde que las soluciones a los siguientes ejercicios deben estar dentro de la carpeta ejercicios/pthreads dentro de su repositorio personal de control de versiones.
1.6.1. Hola mundo ordenado
1.6.2. Área bajo la curva (regla trapezoidal)
1.6.3. Collatz circular
1.7. Concurrencia declarativa (OpenMP)
Recuerde que las soluciones a los siguientes ejercicios deben estar dentro de la carpeta ejercicios/openmp dentro de su repositorio personal de control de versiones.
1.7.1. Área bajo la curva (regla trapezoidal)
2. Concurrencia distribuida
2.1. Distribución homogénea (MPI)
Recuerde que las soluciones a los siguientes ejercicios deben estar dentro de la carpeta ejercicios/mpi dentro de su repositorio personal de control de versiones.
2.1.1. Conteo de primos
2.1.2. La papa caliente
2.2. Distribución heterogénea: aceleración gráfica
La aceleración por hardware (hardware acceleration) consiste en la creación y uso de hardware especializado para realizar tareas más convenientemente (velocidad, precisión, consumo energético) de lo que se puede hacer con software que se ejecuta en un procesador de propósito general (CPU). Ejemplos de aceleradores son los procesadores de señales digitales (DSP), los field-programmable analog array (FPAA), y las unidades de procesamiento gráfico (GPU). Esta sección se enfoque en estos últimos.
Una unidad de procesamiento gráfico (GPU, Graphics Processing Unit), es un hardware que acelera la producción de gráficas que se envían a los dispositivos de despliegue (pantallas, proyectores). Su producción y popularización se debe a la industria de videojuegos, que en los años 80 evolucionarían los arreglos de gráficos de vídeo (VGA, Video Graphics Array) al incluir procesadores especializados (GPU) con conjuntos de instrucciones para procesamiento de vectores y pixeles, como suavizar figuras o producir efectos de sombras. Los programadores aprovechaban esta aceleración con interfaces de programación como OpenGL y DirectX.
(Pendiente)
Referencias
-
[Gram03] Grama, Ananth; Gupta, Anshul; Karypis, George; Kumar, Vipin. Introduction to Parallel Computing, 2nd ed. Addison Wesley, 2003.
-
[Pach11] Pacheco, Peter. Introduction to Parallel Programming. Burlington, MA: Elsevier Inc., 2011.
-
[Silb12] Silberschatz; Galvin, Gagne. Operating System Concepts, 9th ed. Wiley Global Education, 2012.
-
[Will12] Williams, Anthony. C++ Concurrency in Action: Practical Multithreading. Manning, 2012.